25 Mei 2025 –
Automatisch teksten verzamelen
Eén van mijn komende projecten vereist het automatisch extracten van audio data uit gepubliceerde content op YouTube. De mogelijkheden van metadata extractie en data manipulatie in de YouTube omgeving zijn sterk in ontwikkeling en vandaag ga ik deze mogelijkheden praktisch, diepgaand verkennen door het inzetten van Python scripts in combinatie met specifieke libraries. De praktische uitvoering van vandaag heeft als doel het automatisch omzetten van een gepubliceerde top40 lijst naar een set MP3 files welke in een entertainment systeem afgespeeld kunnen worden.
Mijn vertrekpunt is het automatisch ophalen van teksten vanuit de wekelijkse geactualiseerde Top40-website waarin ranking, titel, artiest en link naar YouTube video gepubliceerd staan. Deze site publiceert iedere week een volledige Top40. De gegevens in de HTML-code staan duidelijk gestructureerd, waardoor ik ze makkelijk kan omzetten naar verwerkbare data.
Benodigdheden voor dit project
– Python 3.13
– PyCharm 2501.1
– Python libraries: yt_dlp, tabulate, bs4 – BeautifulSoup
– Website als scrape-object : https://www.top40.nl/top40
– Youtube Playlist : PLC800B9699743BD19
– USB stick
Data structureren en zoeken
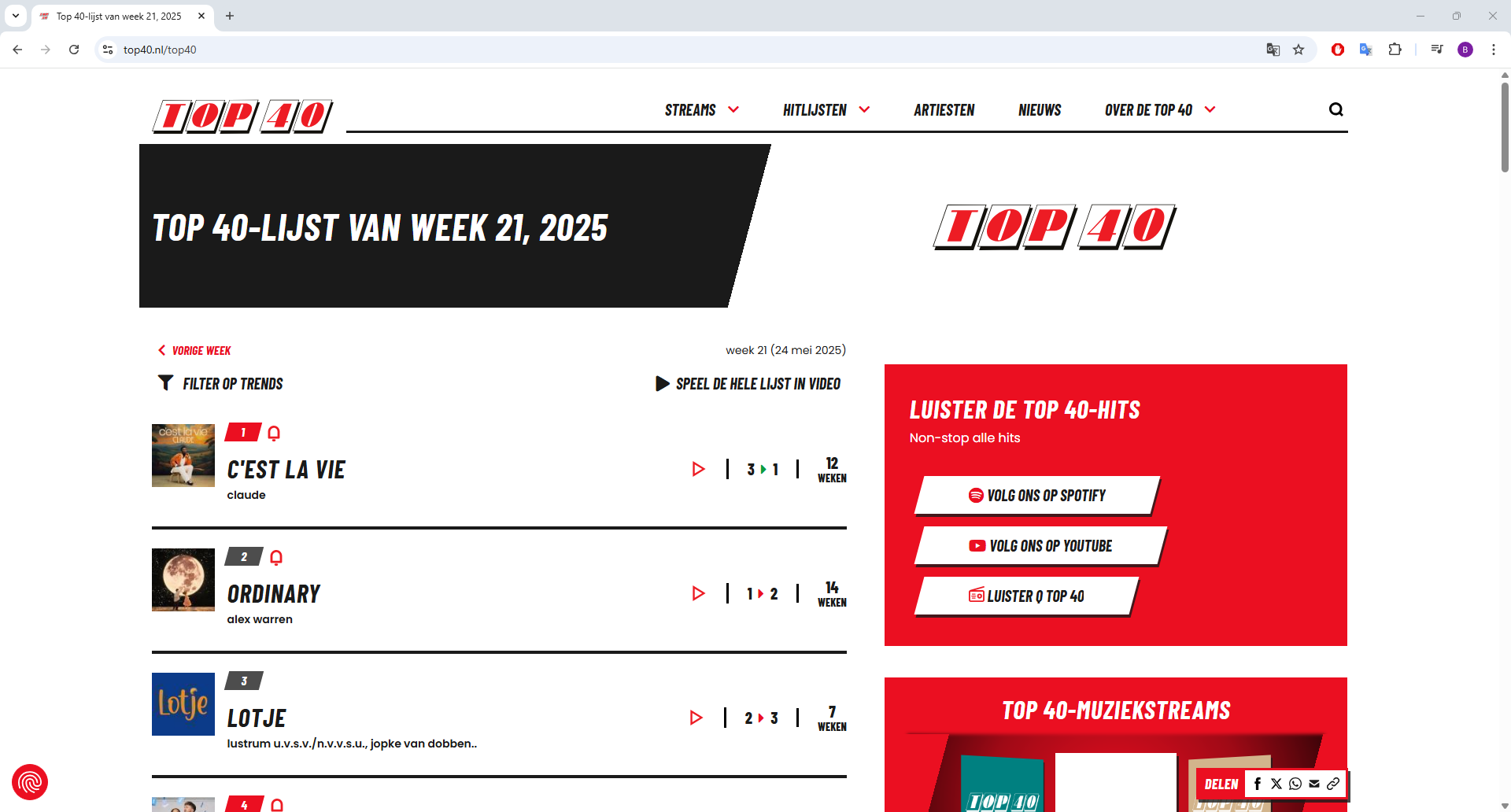
In de bovenstaande top40.nl website zie ik duidelijk onderscheid tussen de positie van het nummer, de titel en de uitvoerende artiest. Ik besluit een lijst te maken met BeautifulSoup, een Python-bibliotheek die ik vaak gebruik om HTML-, XML- of JSON-documenten gestructureerd te doorzoeken. Dit is ideaal voor mijn taak, waarbij ik automatisch repeterende gegevens uit een bron haal. Zo zoek ik op tags, CSS-classes en attributes.
Werken met PyCharm
Ik ga aan de slag met het programmeren in Python met behulp van PyCharm. PyCharm is een gebruiksvriendelijke geïntegreerde ontwikkelomgeving voor Python, gemaakt door JetBrains. Het maakt schrijven, testen en debuggen van Python-code makkelijker en efficiënter. Ook ondersteunt het het integreren en aanroepen van bibliotheken uitstekend.
Data-extractie en problemen
Ik vraag ChatGPT om een overzicht van alle Top40-nummers met positie, titel en uitvoerende artiest. Direct krijg ik een keurig overzicht met een link naar de bijbehorende YouTube-video. Dat is handig, want zo kan ik later automatisch een MP3 downloaden van de YouTube-video en die voorzien van ranking, titel en artiest. Op basis hiervan overtuigt het me dat ik een MP3-export kan automatiseren.

Webscraper maken met BeautifulSoup
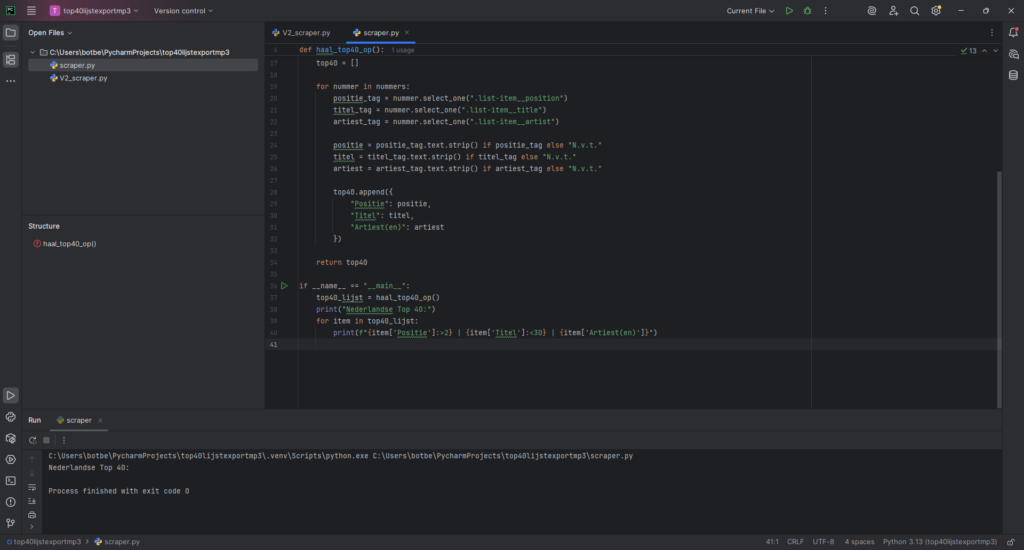
Ik maak een webscraper in PyCharm. Ik creëer een variabele soup = BeautifulSoup(response.text, “html.parser”) om data uit de website te halen en doorzoekbaar te maken. Met list-items haal ik positie, titel en artiest op. Na veel proberen ontdek ik dat de content dynamisch met JavaScript wordt geladen. BeautifulSoup pakt alleen statische HTML, dus blijft mijn extractie leeg. Daarom pak ik de detailpagina’s, waar ik specifieke info over elk nummer vind.
Hier is een voorbeeld van mijn scraper-code die de Top40-nummers ophaalt:
def haal_top40_op():
url = "https://www.top40.nl/top40"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)"
" Chrome/90.0.4430.85 Safari/537.36"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
nummers = soup.select("li.list-item")
top40 = []
for nummer in nummers:
positie_tag = nummer.select_one(".list-item__position")
titel_tag = nummer.select_one(".list-item__title")
artiest_tag = nummer.select_one(".list-item__artist")
positie = positie_tag.text.strip() if positie_tag else "N.v.t."
titel = titel_tag.text.strip() if titel_tag else "N.v.t."
artiest = artiest_tag.text.strip() if artiest_tag else "N.v.t."
top40.append({
"Positie": positie,
"Titel": titel,
"Artiest(en)": artiest
})
return top40Probleem met BeautifulSoup en dynamische content
Na veel puzzelen en aanpassen van mijn code blijft het resultaat van mijn extracties met BeautifulSoup leeg. Ik concludeer dat de website haar content dynamisch laadt met JavaScript. BeautifulSoup werkt samen met de requests-library alleen als de HTML statisch is. Daarom kan ik niet direct de benodigde data ophalen.

Als alternatief besluit ik de detailpagina van elk nummer te scrapen. Deze pagina’s geven me inzicht in de ranking, titel en artiest. Alleen de YouTube-link ontbreekt nog, maar dat los ik later op. In mijn script vraag ik om de URL van de detailpagina en krijg ik alle benodigde data terug.
Scrapen van detailpagina’s met Python
Hier is mijn Python-code waarmee ik de titel, artiest en positie van een nummer op een detailpagina haal:
import requests
from bs4 import BeautifulSoup
import re
def clean_title(title):
# Verwijder " | Top 40" en extra spaties
title = re.sub(r'\s*\|\s*Top 40', '', title)
return title.strip()
def clean_artist(artist):
# Verwijder vaste tekst
artist = re.sub(r'Bekijk de songinfo van ', '', artist, flags=re.IGNORECASE)
artist = re.sub(r' op de officiële Nederlandse Top 40-website\.?', '', artist, flags=re.IGNORECASE)
artist = artist.strip()
# Verwijder alles na en inclusief " - " als dat aanwezig is
if ' - ' in artist:
artist = artist.split(' - ')[0].strip()
return artist
def scrape_top40_song(url):
response = requests.get(url)
if response.status_code != 200:
print("Kon de pagina niet laden.")
return None
soup = BeautifulSoup(response.text, 'html.parser')
# Titel halen uit <title> tag
title_tag = soup.find('title')
titel = clean_title(title_tag.text) if title_tag else None
# Artiest ophalen uit meta description of andere plek
meta_desc = soup.find('meta', attrs={'name': 'description'})
artiest = meta_desc['content'] if meta_desc and 'content' in meta_desc.attrs else None
if artiest:
artiest = clean_artist(artiest)
# Positie ophalen, staat vaak in h2 of div met class 'position'
positie = None
# Probeer positie te vinden in de breadcrumb of andere plek
# Op de pagina zit een div met class "header-info" met positie in h2, bijvoorbeeld:
header_info = soup.find('div', class_='header-info')
if header_info:
positie_tag = header_info.find('h2')
if positie_tag:
# Vaak staat er "Positie 18"
m = re.search(r'Positie\s+(\d+)', positie_tag.text)
if m:
positie = int(m.group(1))
# Fallback: Soms staat positie in andere plekken (e.g. URL)
if not positie:
m = re.search(r'-(\d+)$', url)
if m:
positie = int(m.group(1))
return {
'positie': positie,
'titel': titel,
'artiest': artiest
}
if __name__ == "__main__":
url = input("Voer de URL van het nummer in: ").strip()
data = scrape_top40_song(url)
print(data)Problemen met positie-extractie
Wanneer ik bijvoorbeeld de URL https://www.top40.nl/zoe-livay-feat-snelle/ik-zing-43027 invoer, krijg ik:
{'positie': 43027, 'titel': 'Zoë Livay Feat. Snelle - Ik Zing', 'artiest': 'Zoë Livay Feat. Snelle'}Ik had echter verwacht dat de positie 4 is (zoals in de Top40). Dit betekent dat ik een betere plek moet vinden waar de positie staat. Ik ontdek dat de site de positie specifiek vermeldt in een tag. Dit pas ik nu in mijn scraper aan.
YouTube-link zoeken in HTML
Ik ga op zoek naar de YouTube-video van het nummer. Deze is vaak embedded in de pagina via een of een directe link. Na zoeken vind ik een <div class=”video__player”> met een iframe waarvan de src verwijst naar YouTube. Hiermee kan ik de juiste video-URL achterhalen. Dit geeft me de video, maar ik krijg nog niet tegelijk de ranking erbij.
YouTube-playlists als alternatief
Ik realiseer me dat de Top40-nummers wekelijks ook in een officiële YouTube-playlist staan. Deze playlist is geen website, maar wel een gestructureerde bron die ik kan analyseren. Hierdoor kan ik eenvoudig een lijst met nummers, video-URL’s, duur, kanaalnaam en meer ophalen.
Video details uitlezen met Pytube
Ik gebruik de Python-bibliotheek Pytube (ontwikkeld in 2014) om de playlist te analyseren en video’s te downloaden. Hier is een voorbeeldcode:
from pytube import Playlist, YouTube
import time
playlist_url = "https://www.youtube.com/playlist?list=PLC800B9699743BD19"
pl = Playlist(playlist_url)
print(f"Playlist titel: {pl.title}\n")
print(f"{'Nr':<3} {'Titel':<60} {'Kanaal':<30} {'Duur':<8} URL")
for i, video_url in enumerate(pl.video_urls, start=1):
try:
video = YouTube(video_url)
title = video.title
channel = video.author
duration = time.strftime('%M:%S', time.gmtime(video.length))
print(f"{i:<3} {title[:57]:<60} {channel[:27]:<30} {duration:<8} {video_url}")
except Exception as e:
print(f"{i:<3} Error bij video: {video_url} - {e}")
time.sleep(1)Nadelen van Pytube en overstap naar yt-dlp
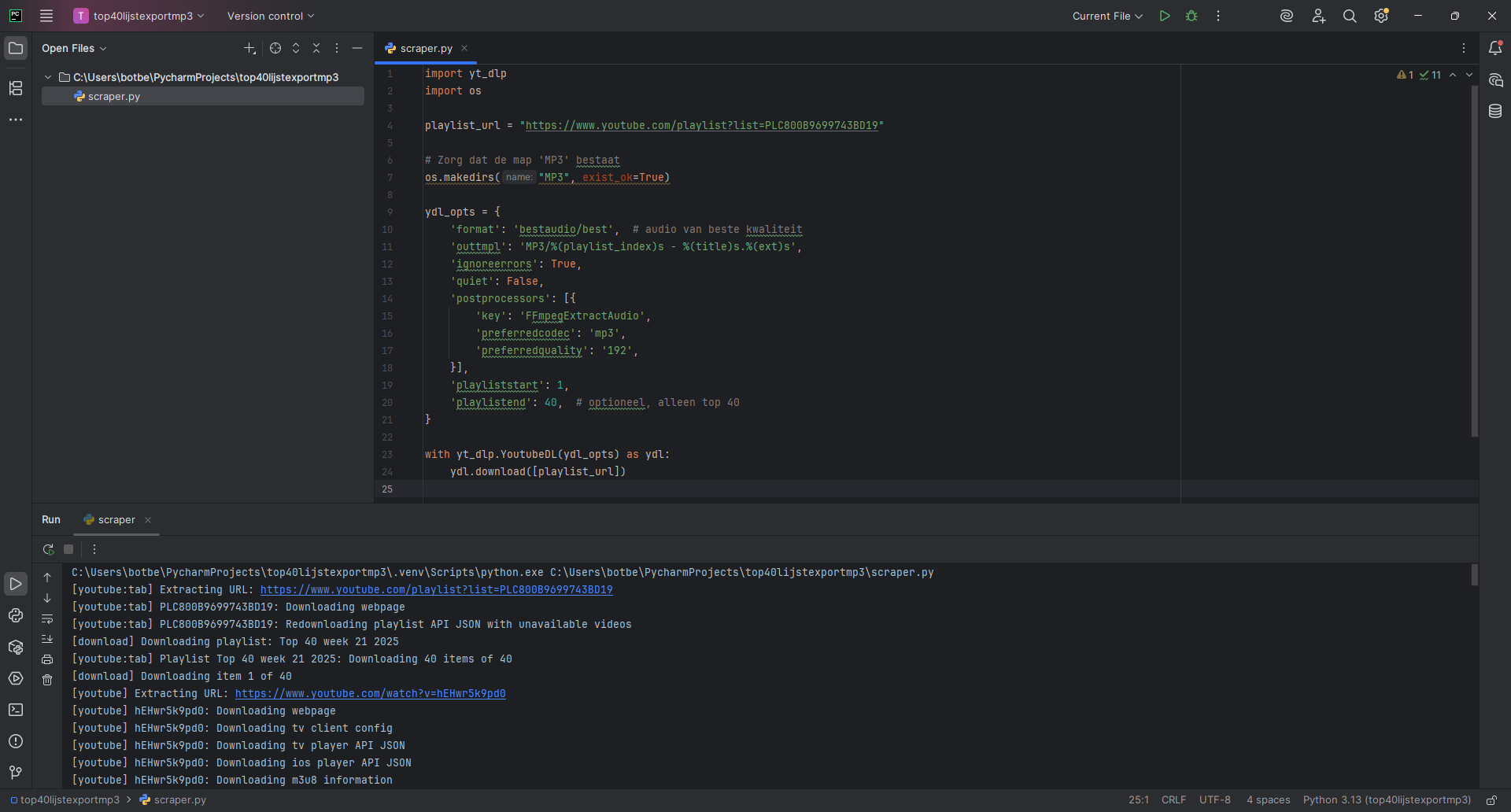
De playlist.videos functie van Pytube werkt traag en is foutgevoelig. Om het stabieler te maken, gebruik ik een try-except blok om fouten op te vangen. Een beter alternatief is yt-dlp, een fork van youtube-dl uit 2020, die krachtiger en veelzijdiger is. Deze library downloadt audio en video, ondersteunt playlists, kan automatisch MP3’s maken en metadata bewerken. Voor het aanroepen van de yt-dlp libarry en het kunnen opslaan van files moeten zowel de yt-dlp als de os library aangeroepen worden:
import yt_dlp
import osOm een specifieke playlist te downloaden, definieer ik een nieuwe variabele. Deze variabele heet playlist_url en verwijst naar de URL die binnen YouTube wordt gebruikt om een playlist op te halen:
playlist_url = "https://www.youtube.com/playlist?list=PLC800B9699743BD19"Vervolgens moet er een plek worden gereserveerd om de MP3-bestanden op te slaan. De naam van deze map kan dynamisch worden aangepast en eventueel verwijzen naar de naam van de YouTube-playlist. Voor nu kies ik voor een map met de naam MP3:
# Zorg dat de map 'MP3' bestaat
os.makedirs("MP3", exist_ok=True)In de variabele ydl_opts staan de opties waarmee de downloadmodule wordt aangestuurd. Dit betreft onder andere de gewenste kwaliteit van het formaat, en de outputparameters waarin ik het playlistnummer, de titel en de uitvoerende artiest wil opnemen in de bestandsnaam. Ook wil ik dat het programma bij fouten niet stopt, maar doorgaat met de volgende video. In de postprocessor wordt de audio met behulp van FFmpeg omgezet naar MP3, met een audiokwaliteit van 192 kbps. Om te voorkomen dat de hele playlist onnodig lang wordt gedownload, en omdat ik weet dat er 40 nummers in zitten, stel ik de start- en eindpositie van de playlist in op respectievelijk 1 en 40.
ydl_opts = {
'format': 'bestaudio/best', # audio van beste kwaliteit
'outtmpl': 'MP3/%(playlist_index)s - %(title)s.%(ext)s',
'ignoreerrors': True,
'quiet': False,
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}],
'playliststart': 1,
'playlistend': 40, # optioneel, alleen top 40
}Om het extractieproces te starten, wordt de functie yt_dlp.YoutubeDL aangeroepen en wordt de playlist_url doorgegeven:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([playlist_url])Hiermee is het volledige programma klaar. De complete code omvat slechts 24 regels. Door het aanpassen van playlist_url kan elke YouTube-playlist automatisch worden geëxtraheerd naar een verzameling MP3-bestanden, bijvoorbeeld voor eigen gebruik in de auto. Hieronder staat het volledige programma weergegeven.
import yt_dlp
import os
playlist_url = "https://www.youtube.com/playlist?list=PLC800B9699743BD19"
# Zorg dat de map 'MP3' bestaat
os.makedirs("MP3", exist_ok=True)
ydl_opts = {
'format': 'bestaudio/best', # audio van beste kwaliteit
'outtmpl': 'MP3/%(playlist_index)s - %(title)s.%(ext)s',
'ignoreerrors': True,
'quiet': False,
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}],
'playliststart': 1,
'playlistend': 40, # optioneel, alleen top 40
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([playlist_url])
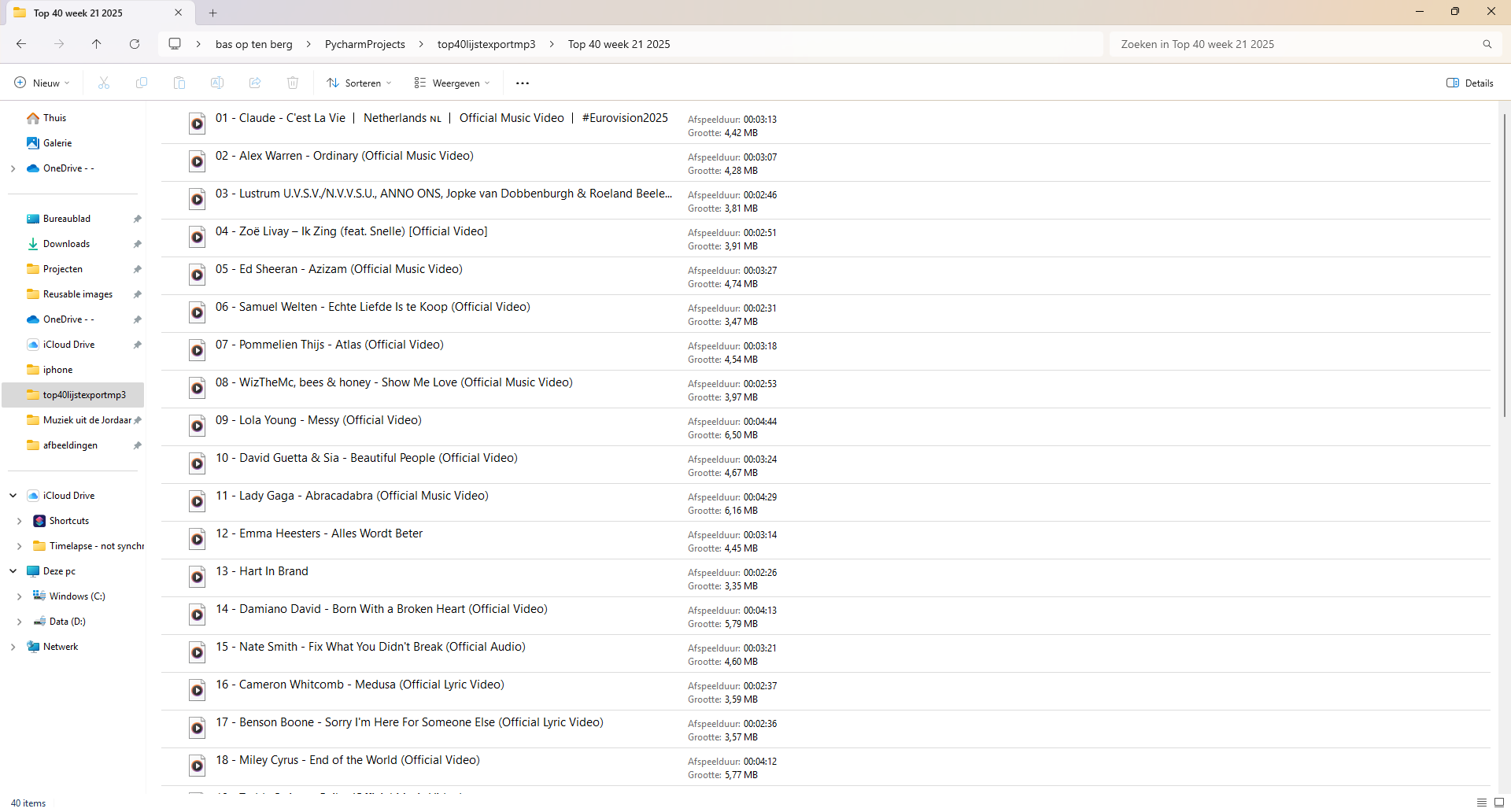
Conclusie: automatiseren van data-extractie en bestandsconversie
Het automatisch extraheren van data uit online bronnen is fascinerend. Wanneer data elektronisch en gestructureerd beschikbaar is, kan ik die data manipuleren om processen aan te sturen.
In dit voorbeeld zet ik een URL met een lijst van nummers om in een dataset met ranking, artiest, titel én YouTube-video. Die video gebruik ik om MP3’s te maken met automatisch gegenereerde bestandsnamen.
Dit soort automatisering werkt niet alleen voor mediabestanden, maar kan ook slimme systemen aansturen, zoals het starten van apparaten, het regelen van verlichting, home automation of het triggeren van MQTT-calls. De mogelijkheden zijn enorm breed en spannend. In dit geval ook erg praktisch. Dank zij deze geautomatiseerde download is mijn autoradio weer voorzien van een actuele Top40 nummers.